Introducing streamy-db: a deterministic database on top of a stream processing engine
In this post I’ll introduce streamy-db and explain the theory behind it.
TLDR: streamy-db is distributed deterministic (Calvin inspired) database (transaction processing system) implemented on top of a stream processing framework (apache Beam / Flink).
Currently it’s in an early prototype phase, but the possibilities are endless. My hope is to motivate some of you to join me on the journey!
I’ll first introduce Calvin, next get to the essence of deterministic transaction processing, then give a short description of stream processing, and finally we’ll get to a description of how the prototype is implemented and what lays ahead.
Calvin: Fast Distributed Transactions for Partitioned Database Systems
This 2012 paper describes a scalable deterministic database system.
Deterministic databases solve the (distributed) transaction processing problem in an interesting way. As a first step a global ordering is determined for all transactions. Next this globally ordered stream of transactions is processed as if all transactions were executed sequentially.
Any non deterministic effects such as generating a random number or getting the current time have to be done beforehand, and stored as part of the transaction inputs. This has as an advantage that there could be multiple systems (in different datacenters) processing the same transactional input stream independently, yet arrive at the same outputs. It also makes recovering from failures easier and cheaper.
For more info about these kind of systems I definitely suggest having a look at the blog of Daniel Abadi, he has written some interesting blogs related to the topic.
Calvin splits the system in three separate layers:
- sequencing layer: determines a global order for all transactions
- scheduling layer: orchestrates transaction execution (this is the tricky part)
- (non transactional) storage layer
Next it shows how these 3 layers can each be scaled independently.
In short, the sequencing layer can be scaled by having multiple streams in parallel, and periodically committing the offsets of the individual streams into a ‘master’ stream.
The storage layer could be basically any scalable (non transactional) nosql key-value store.
The scheduling layer calculates the result for a batch of transactions (e.g. every 10ms). Each executor is reponsible for a shard of the key range. Processing is done in the following phases:
- send each transaction of the batch to all involved executors
- on each executor read all keys for the transactions of the current batch
- send read results to other executors
- all executors can now calculate result (commit/abort) for the transaction they were involved in
- send output to the storage layer
I would call this a micro-batched approach (in contrast to a streaming approach), in which sharding is done on the granularity of a shard/executor. Probably I’m not explaining it entirely correctly, but instead of dwelling on that, let us be inspired by this approach, yet take a step back.
The essence of deterministic transaction processing
Let us consider for a moment what it means to process a transaction T at timestamp t0 in deterministic system:
- read inputs at t0
- determine transaction results
- write outputs at t0
Graphically this would look as follows:
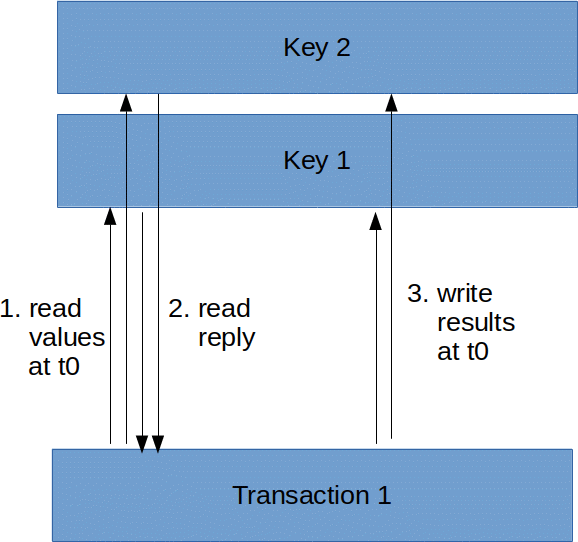
I’m a bit vague in the above about what ‘read at t0’ and ‘write at t0’ means. Conceptually it happens at the same time. The easiest implementation is that all transactions are processed sequentially. In reality latency is everywhere, and we want many transactions to be able to process concurrently.
In order to allow processing multiple transactions concurrently while still ensuring correctness we must disentangle our description a bit:
- read inputs and lock outputs at logical time t0
- determine transaction results
- write outputs at logical time t0, releasing the earlier locks
Or in picture form:
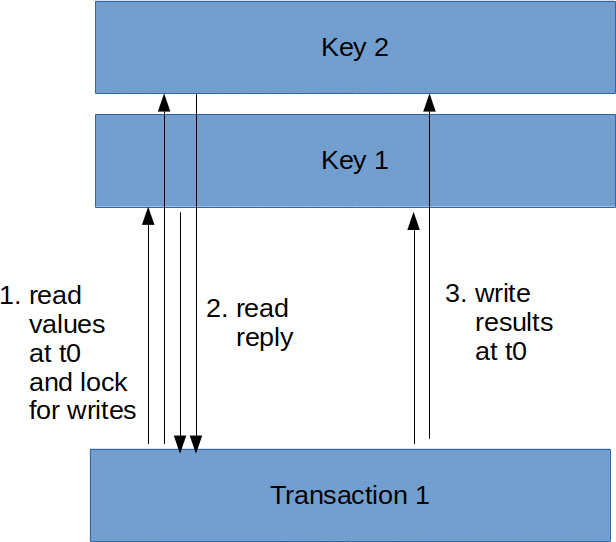
With this new view of what processing a transaction means it now becomes clear for each key we’ll need a little state machine that allow reading the value at a certain timestamp, locking at a timestamp, and writing a value to release an earlier lock.
Let us now define what a transaction could look like on e.g. a simple key-value store:
class Transaction {
Map[Key, Option[Value]] asserts
Map[Key, Option[Value]] updates
}
A transaction expresses that assuming some current state of the database Map[Key, Option[Value]] asserts
it should be updated with a set of writes Map[Key, Option[Value]] updates.
Given this model, and the earlier description of what it means to process an transaction, and the need for a mini state machine per key (which I’ve called KeyTransactionProcessor), what we would now like to achieve is the equivalent of the following picture:
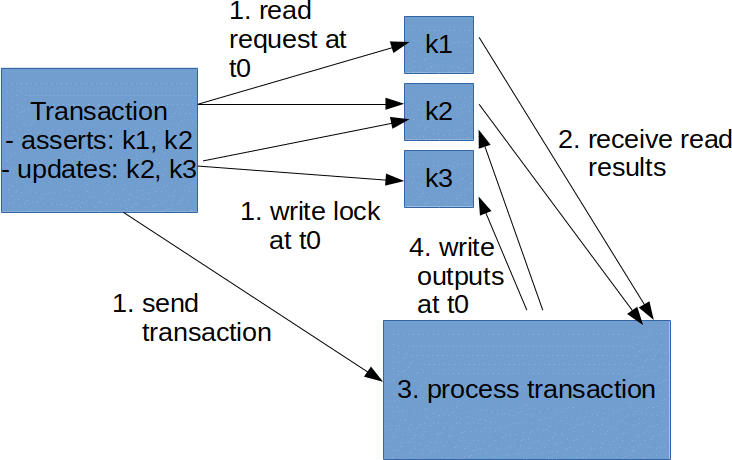
In which this flow is continuously ongoing for many transactions at once.
How can we implement such a system (efficiently), and also how we would handle failures?
To solve that problem, let us take a short look at stream processing, and the concept of event-time and watermarks.
Stream processing
The stream processing model comes from Google Cloud Dataflow, and is now known as Apache Beam. One particularly interesting implementation of this model is Apache Flink.
Recommended literature: Streaming 101 and 102. I’ll give a very short summary here.
Stream processing is the latest incarnation of big data processing tools. It is an improvement upon the micro-batching offered by technologies such Apache Spark (which itself was an improvement over map-reduce style computations such as in Hadoop).
Stream processing allows parallel execution of map, reduce and keyBy operations. It has low latency, built-in failure recovery capabilities, and can do at-least-once or exactly-once processing.
There is also the option of having more generic stateful operators, see here for a good description.
An important (powerful) concept in stream processing engines is the concept of event time and their associated watermarks. Event time allows timestamping the events (data) that is be analyzed, such that the events can be grouped into e.g. fixed time windows, sliding windows, (user) sessions, …
Now, if you want to group data that is arriving in a stream, that may be partially out of order, into windows, you must be able to know when you’ve seen all data. This is what watermarks are for. Watermarks flow (at least conceptually) as part of a (parallel) datastream, and allow operators to know (have guarantees) about completeness of the input (up to a certain point). A good explanation can be found in the flink documentation.
This short description is probably not enough for people unfamiliar with the concept, so I do recommend to check out some of the links.
A good understanding of stateful stream processing and event-time/watermarks is probably beneficial going from this point forward. So do click through on those latest 2 links if you feel that I’m going too fast in the next sections.
That being said, let’s circle back to deterministic transaction processing.
Implementation on top of a stream processing engine
First we consider the input of our deterministic system: the recording and ordering of transactions to be executed. This can be easily done using e.g. a partitioned kafka topic which timestamps all records using log append time. A flink job (or beam pipeline) can read and process the different partitions of the topic in parallel. (Additionally we also add a heartbeat generator to ensure watermarks for all partitions are generated periodically, so the streaming computation keeps on making progress)
Recapping from earlier, for the transaction processing we want to implement the equivalent of this picture:
In a more stream processy view we can draw it as follows:
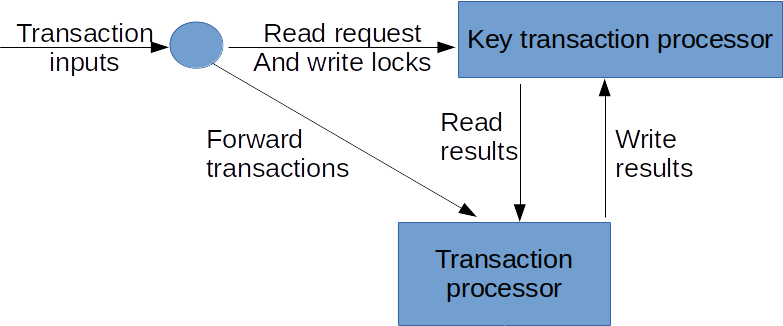
We can now identify multiple streams:
- incoming transactions
- read-requests and write-locks
- read-results
- write results
We also see that the KeyTransactionProcessor node that we introduced takes 2 inputs. So it must union/connect 2 streams. However the read-requests and write-locks stream (2) could be partially out of order! By default the stream processor only gives us guarantees whenever we see a watermark. And if we mix in the write results stream (4), then we can no longer reason about the watermarks of stream 2.
To solve this problem we introduce the KeyedEventTimeSorter. It is a stateful keyed processing function, that use local state and watermarks (eventtime based timers) to order stream 2.
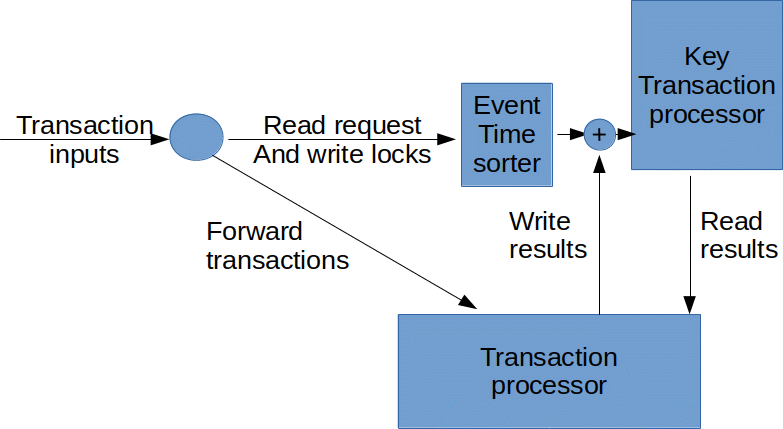
Now we have all components in place. The circle is a relatively simple map step. The other components are described below.
The KeyTransactionProcessor, for each key:
- keeps state (associated value, if any)
- should receive an ordered stream of timestamped read requests and write locks
- receives a stream of transaction results (to complete a corresponding write lock)
- for read locks (requests) wait to send out the read result until there are no more preceding write locks
The TransactionProcessor, for each transaction:
- receives all reads
- receives the transaction (asserts & updates)
- outputs the result
There is 1 detail not yet described: how are the write results fed back into the KeyTransactionProcessors? Streaming computations form a DAG (directed acyclic graph), and flink/beam seem to offer no Pipe component (that I could find).
In the prototype this is solved by using a extra kafka topic that is both read from and written to in the job. I’m sure that using a ‘Rich’, ‘Checkpointed’, ‘Sink’, ‘Source’ function (to use some flink specific terminology) it should be possible to achieve the same in a more efficient manner, but that is work that remains to be done.
If you clicked on the links above you’ll see that in less than 500 lines we were able to express the entire logic that makes our system. Which is surprisingly little code for what it achieves (scalable transaction processing). I’m big believer of less is more, so for me this is a beautiful result.
It maximally leverages the stream processing framework to do the heavy lifting. This has some pros and cons.
cons:
- less customisable (e.g. towards quality of service for different users or which stream you would actually want it to prioritise…)
- no built in range based sharding (although one could implement a tree/index as a layer on top?)
pros:
- all the stream processing pros (low latency, built in failure recovery, scalable, …)
- fewer chances of bugs, as there isn’t much code
- built-in change data capture
- integrates perfectly with other stream processing needs you may have
Recap, and taking a step back
So what have we done? How does it work?
The trick lies in the KeyedEventTimeSorter. It enables sending read-requests and write-locks to the KeyTransactionProcessor on specific (logical) timestamps, and leave the rest of the system maximal flexibility (freedom, leeway) to schedule processing whenever it is most convenient. The KeyTransactionProcessor implements the deterministic locking scheme.
Of course there’s nothing special about read-request or write-lock messages. We could for example also send a get-next-id message, with the obvious semantics, that don’t result in locking (aka waiting for a write result to finally arrive). With some creativity plenty of other messages are possible too, and we can look at the KeyTransactionProcessor as a more generic (virtual) actor.
Related work
Streaming ledger from da-platform (aka data artisans), the main developers of apache flink. They don’t say how it works, but I can only guess that it’s quite similar to this approach.
FaunaDB is based on Calvin, so also a deterministic database. However theirs is (as far as I understood) not a streaming implementation.
What’s next
Well, there are plenty of existing databases on the market already… and I’m just a 1 man army. But I really believe this approach has much potential. And I hope I’ve been able to convince at least some of you of that.
If other people want to jump in, then there’s many things we can do together.
Short term more practical improvements
- push (part of) this documentation-by-blog-post into the repository
- build simple key-value rest API to allow submitting transactions, reading keys. show example usage
- build a better pipe mechanism that doesn’t require an extra kafka topic (to feed back write results to the KeyTransactionProcessors)
- implement model where KeyTransactionProcessors send all read results to each other (for transactions with few keys this is probably an optimisation, it’s also closer to the original Calvin description)
- package the code for easy distribution (jar on maven, image on dockerhub, …)
- tests! (correctness & performance)
- expose flink queryable state
Longer term more dreamy and inspiring goals
If you want to build a ship, don’t drum up the men to gather wood, divide the work, and give orders. Instead, teach them to yearn for the vast and endless sea.
– Antoine de Saint-Exupéry
I guess these only make sense after doing most of the short term goals, but it’s important to already start thinking about them now. The descriptions may be a bit terse, but that’s intentional. I want to leave plenty of space for other people to join in with their ideas.
- implement ‘layers’ (e.g. document, graph, sql) on top of the key-value model
- virtual actors model (a la orleans or AMBROSIA)
- multiversioned database backend to allow strongly consistent reads at arbitrary point in the past
- keep state mainly in a separate backend (e.g. the multiversioned one from the previous bullet point), and only load state into the stream processor for keys participating in transactions?
- … ???
- profit :)?
Closing words
Come and join me at https://github.com/domsj/streamy-db, we’ll have fun together!